
Big data. Smak på ordene. De er egnet til å skremme vannet og pengene ut av CIO-en. Eller it-sjefen for å bruke et litt kjedeligere norsk ord. Kanskje er det litt av hensikten. For det virker.
Skal it-forskere få penger fra Forskningsrådet eller EU, så er det en klar fordel å nevne Big data i søknaden. Big er det som trigger alt fra servere til lagring, og «biggere» skal det bli.


Voldsom vekst
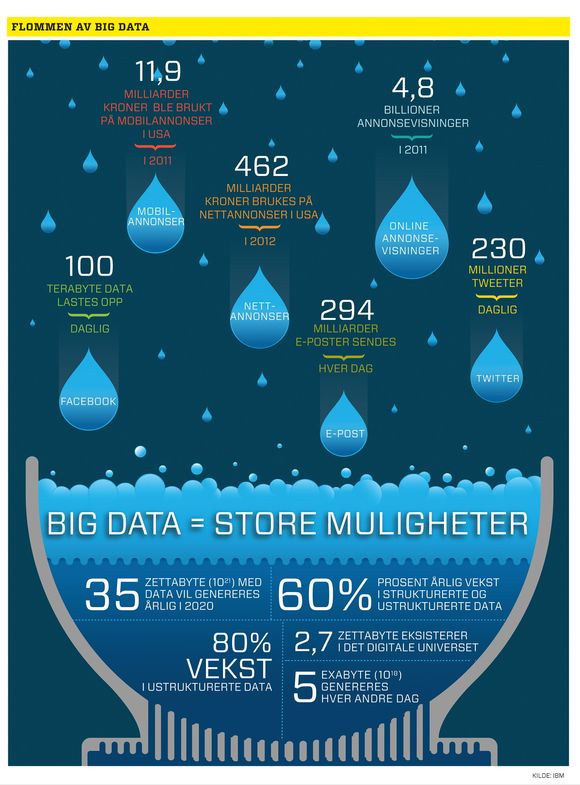
Det er jo nesten ikke ende på dataveksten og vi sliter med å få verdi ut av fjellet av ettall og nuller. Dessverre er det ingen entydig definisjon på hva Big data er. Alle har en som passer til det de selger.
Spør du en lagringsleverandør som EMC eller HDS, så heller nok de til at dette handler om å lagre stadig mer og håndtere veksten som kommer. En databaseleverandør vil si at det nå gjelder å sørge for skalerbarhet slik at det blir plass til alt som skal inn i databasene.
SAP vil si at det holder ikke. Skal vi få fart på sakene må vi ha databaseteknologi som kan jobbe fra enorme RAM-lagre og ikke fra disk.
Mens de som driver med analyse, slik som SAS Institute, vil si nå gjelder det å få noe fornuft ut av dataene samtidig som alt vokser. Mens andre vil peke på sensordata som strømmer inn som den rene vårflommen og at vi må forberede oss på mer flom.
Les også: Dette risikerer du ved å lagre filer i nettskyen
Vil få bort synsing
Litt spøkefullt kan man si at dagens beslutninger er basert på hva Hippo mener, det vil si highest paid person’s opinion.
Et viktig mål med Big data er å kunne ta bedre beslutninger basert på informasjon som virksomheten allerede har tilgang til i egne datakilder. Datadrevne beslutninger og ikke synsing.
Problemet stadig flere står overfor er at mengden data de har er stor og uhåndterlig og øker i voldsom takt.
Databasene sveller ut og ustrukturerte data i form av alle slags dokumenter øker enda raskere. Nesten eksplosivt for mange.
Klassisk løsning
Den klassiske løsningen på dataveksten er å kjøpe større datalager, mer nettskykapasitet og så videre. Men slike løsninger kan på sikt øke problemet.
Det blir ikke enklere å hente verdier ut av et fjell som vokser i akselererende takt. Skal dataene ha noen verdi for beslutningstakere må de kunne behandles raskt.
En fornuftig måte å betrakte det populære slagordet på er at det handler om hele kjeden fra datafangst, behandling og lagring til hvordan dataene kan gjøres tilgjengelige gjennom administrasjonsverktøy, søk, analyse og hvordan de kan visualiseres.
Les også: Vi jobber mer og bedre med private dingser
.jpg)
Fra alle kanter
Det er ikke bare forretningsbeslutninger som trenger ny teknologi. Alle slags sensorer, weblogger, sosiale data og dokumenter rundt om i samfunnet formelig spyr ut potensielt verdifulle data.
Meteorologer, de som styrer trafikk, energi, sikkerhetssystemer, innen medisin og forskning og etter hvert de fleste av oss, kan ha stor nytte av alle slags data som er tilgjengelig.
Den nye partikkelakseleratoren ved CERN genererer så mye data at prosessering og lagring er fordelt over hele Europa.
Bedrifter og organisasjoner er nødt til å etterleve offentlige krav til å ta vare på dataene og til å kunne gjenfinne dokumenter på kort tid.
Poenget er at vi kan få mye mer ut av det vi allerede har og de data som strømmer mot oss fra alle kanter, om vi kan få verktøy som kan omsette dette til utnyttbar informasjon i tilnærmet sanntid.
Til syvende og sist er det analysen av informasjonen som gir verdi. Det er her regnbuen ender og det vet de som leverer slike verktøy.
Allerede i Romertiden ...
Når mengden data øker blir det vanskelig å få fornuftige svar raskt med tradisjonell teknologi. Derfor må problemet brytes opp i biter og behandles i parallell, men det er heller ikke enkelt. For det må skje på en koordinert måte.
Det kan sammenliknes litt med å bygge et hus veldig fort med tusen snekkere. De fleste skjønner at det ikke går tusen ganger fortere. Men det kan gå fryktelig raskt om snekkerne blir koordinert på en veldig god måte.
Det er her teknologi som kalles Map Reduce og Hadoop kommer inn. Map Reduce er en teknologi som Google har utviklet for å splitte opp slike problemer og få dem behandlet i parallell på et stort antall servere. Hadoop er en åpen kildekodevariant av det samme som er blitt veldig populært, og som mange av dem som driver med Big data benytter.
En analogi til Map Reduce er måten romerne drev folketelling på, eller som det står i bibelen; «da all verden skulle innskrives i manntall».
De sendte folketellere ut i Romerriket og hver skulle telle folk innenfor en by eller et område, altså mapping. Det foregikk i parallell. Så ble resultatene samlet inn i Roma og lagt sammen, altså redusert til ett, eller noen tall.
I minnet
En av utfordringene med store databaser og mye informasjon er at det tar tid å få svar. Hastighet er viktig. En lovende teknologi som alle de store databaseleverandørene arbeider med er såkalte in memory-databaser. Tradisjonelt har store databaser blitt lagret i diskbaserte systemer, men de er trege.
De som er kommet lengst med denne teknologien er SAP med sin Hana in memory-database. SAP hadde fordelen av at de ikke hadde en egen database (med unntak av Sybase, som de hadde kjøpt, men som er mye mindre enn de store). Derfor kunne de utvikle de nye ideene uten å skade den installerte basen.
En løsning har vært å bruke flashminne for å erstatte disk for å øke hastigheten. Men ingen ting slår in memory.
Her lastes all informasjonen inn i et stort DRAM-lager. Det er samme type minne som vi bruker i pc-er og servere og som kobles så nært prosessoren som mulig. Et eksempel på hva som går an er da IBMs Watson-datamaskin, som i fjor vant over de to amerikanske mesterne i Jeopardy.
Ikke bare jobbet over tre tusen prosessorkjerner i parallell, maskinen hadde også 16 terabyte med DRAM hvor hele Wikipedia og svært mye annen informasjon lå klar til bruk. Et tradisjonelt datalager ville vært sjanseløst.
Les også:
Dette endrer hele IT-landskapet






