Å vite sånn noenlunde hvor vi finner bokstavene på et tastatur, er en del av jobben for oss journalister. Men mange yrkesgrupper sliter med å få til en effektiv kommunikasjon med de stadig økende antall nettbaserte tjenester vi etter hvert alle blir avhengige av å betjene. Dessuten kan ulike funksjonshemninger gjøre det vanskelig å betjene et PC-tastatur. For ikke å snakke om de mer eller mindre knotete mobiltelefon- og PDA-tastaturene.
Det ville vært fint å kunne snakke til PC-en og de mindre håndholdte terminalene vi utstyrer oss med. Et talebasert grensesnitt gjør interaksjon mellom mennesker og ulike digitale tjenester mer naturlig og effektiv

Ulempe å være norsk
Taleteknologi er et komplisert emneområde hvor mange faktorer spiller inn. Det er helt klart en ulempe å være norsk i denne sammenhengen. Norsk er en liten språkgruppe, og store deler av talebaserte systemer må skreddersys for det enkelte språk.
Ulike dialektiske innslag gjør heller ikke jobben lettere for de som forsker på taleteknologi. Og det er det faktisk mange miljøer som gjør, ikke bare i det store utland, men også i Norge.
Taleteknologi kan defineres som den delen av språkteknologien som omfatter maskinell bearbeiding av talt språk. Området omfatter således både talegjenkjenning og talesyntese, og dessuten mer tradisjonelle temaer som talekoding som blant annet brukes i forbindelse med mobiltelefoni.
I de siste årene er begrepet taleteknologi utvidet til også å omfatte dialogsystemer, hvor taleteknologi utgjør brukergrensesnittet.
Forskning og utvikling innen talesyntese er i dag kommet relativt langt med tanke på å kunne gi akseptabel ytelse for kommersiell bruk. Dette gjelder imidlertid kun for store språk. På norsk er ennå ikke kvaliteten god nok for massemarkedet.
Vanskelig
Også innen talegjenkjenning er det gjort store framskritt internasjonalt, men det er likevel en lang vei å gå før systemer med akseptabel ytelse er generelt tilgjengelige. De systemene som dominerer er basert på et begrenset vokabular og stilisert eller opplest tale. Akseptabel ytelse er som regel også basert på at systemet benyttes i omgivelser som for eksempel et stille kontormiljø.
Det forventes at taleteknologi vil få et kommersielt gjennombrudd på bred basis først når man kan snakke med et system på samme måte som med et menneske. Med andre ord vil systemet måtte forstå/tolke naturlig tale basert på et tilnærmet ubegrenset vokabular, og ytelsen må være tilfredsstillende iallfall for de mest typiske omgivelsene
BRAGE
Mye av den norske forskningen på dette feltet er organisert i BRAGE, et samarbeidsprosjekt mellom NTNU, Telenor FoU og Sintef Tele og Data og støttet av Norges forskningsråd. Både prosjektdeltakerne og programstyret i Forskningsrådet mener det er avgjørende at prosjektet legger vekt på anvendelser og områder hvor man tror folk flest vil bruke denne teknologien i hverdagen.
Brukervennlighet og brukerbehov er nøkkelord som indikerer for hvor fort og i hvor stor grad folk flest vil ta i bruk denne teknologien. Mye av innsatsen settes derfor inn på å utvikle systemer som kan basere seg på naturlig spontan tale.

Fremtidens maskingrensesnitt vil ha mobiltelefon-format med multimodalt påtrykk, blant annet tale, og respons som kan være tale, tekst, grafikk etc. Prosjektet vil derfor fokusere praktiske og brukervennlige løsninger for multimodale brukergrensesnitt med komplementære påtrykk.
– En del av målet med prosjektet er også å utdanne fire doktorgradsstudenter samt utarbeide minst fem internasjonale publikasjoner pr. år, sier prosjektleder Magne Johnsen ved Institutt for elektronikk og telekommunikasjon, NTNU.
Demonstrator
Utvikling av en demonstrator med enkelte utvalgte anvendelser av ulik kompleksitet er en sentral del av prosjektet. En demonstrator vil både synliggjøre resultatene fra prosjektet spesielt og potensialet til taleteknologi generelt. Anvendelsene på demonstratoren vil videre fokusere og synkronisere arbeidet innenfor prosjektet.
Doktorgradsarbeider vil bli utført innenfor strategiske og langsiktige forskningsoppgaver.
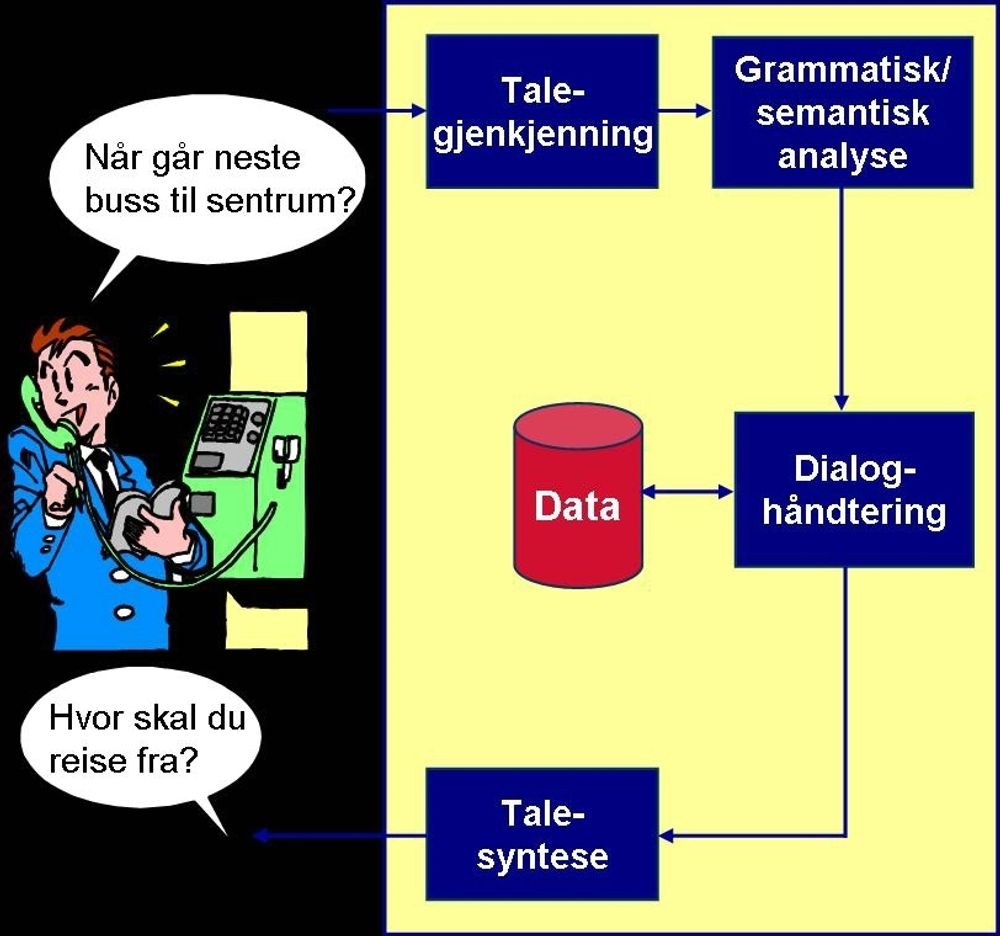
Demonstratoren tar for seg bussruteopplysninger i Trondheim. Dette har også vært gjort i et tidligere forsøk. Den gang var hele prosessen systemstyrt. Det vil si at alle spørsmålene ble generert av maskinen.
– Men nå er vi i ferd med å utvikle en mer fleksibel versjon hvor brukeren kan spørre om alt i en setning. For eksempel: Når går neste buss fra Lade til Lerkendal. Dersom systemet registrerer mangler ved spørsmålet, for eksempel at angitt holdeplass ikke eksisterer, vil det spørre tilbake, sier Erik Harborg, forsker ved Sintef IKT.
Automatisk TV-teksting
Sintef har også utviklet et system for teksting av direktesendte TV-programmer, basert på automatisk talegjenkjenning. Under sendingen lager en kommentator et sammendrag av det som blir sagt programmet. Kommentarene mates inn til en automatisk talegjenkjenner, og den gjenkjente teksten mates inn i kringkastingsselskapets tekst-TV-system.
Denne anvendelsen vil gi hørselshemmede en mulighet til å følge med på direktesendte TV-programmer, dvs. når tekstingen ikke kan gjøres på forhånd.
Den viktigste fordelen med å benytte en talegjenkjenner i stedet for et stenografibasert system er vesentlig kortere opplæringstid for operatoren. Dessuten vil tekstmengden som genereres i et stenografibasert system ofte bli så stor at det blir vanskelig for seeren å få med seg alt, sier Harborg.






